Artificial Intelligence is rapidly becoming embedded in everything from customer support chatbots to internal enterprise workflows. But as organizations accelerate adoption, a new reality is emerging:
Artificial Intelligence introduces an entirely new attack surface.
The OWASP Top 10 for LLM Applications and Generative AI 2025 highlights the most critical security risks facing Large Language Models and generative AI systems today, including prompt injection attacks, data leakage, model poisoning, and AI supply chain vulnerabilities. As AI systems become more autonomous and deeply integrated, these risks are no longer theoretical; they are active attack vectors.
A language model is an AI system that can predict or generate human-like text.
What Is the OWASP Top 10 for LLM Applications?
The OWASP Top 10 for Large Language Model Applications started in 2023 as a community-driven effort to highlight and address security issues specific to AI applications. The OWASP Top 10 for LLM Applications is a community-driven security framework designed to identify and address vulnerabilities specific to AI systems.
The 2025 version is an updated version of the 2023 OWASP Top 10. The 2025 list reflects a better understanding of existing risks and introduces critical updates on how LLMs are used in real-world applications today. There are new additions to the 2025 list:
- Excessive Agency
- Vector/Embedding Weaknesses (RAG risks)
- Unbounded Consumption
What Changed Between OWASP LLM Top 10 (2023 – 2025)
The risk landscape evolved from “Emerging Risks” to “Operational Reality”.
2023:
- Focused on introducing AI/LLM risks
- Many risks were theoretical or early-stage
- Organizations were still experimenting with AI
2025:
- Based on real-world deployments and attacks
- Reflects: Enterprise adoption, Production use cases and Actual exploit patterns
Other changes include: Rise of Agentic AI, the expansion of AI Supply Chain Risks, a new focus on RAG (Retrieval-Augmented Generation), Identity & Access Risks becomes more explicit, addition of “Unbounded Consumption”, and Prompt Injection becomes the number one priority risk.
The 2023 OWASP LLM Top 10 warned us about AI risks, while the 2025 version shows us that those risks are already here and expanding.
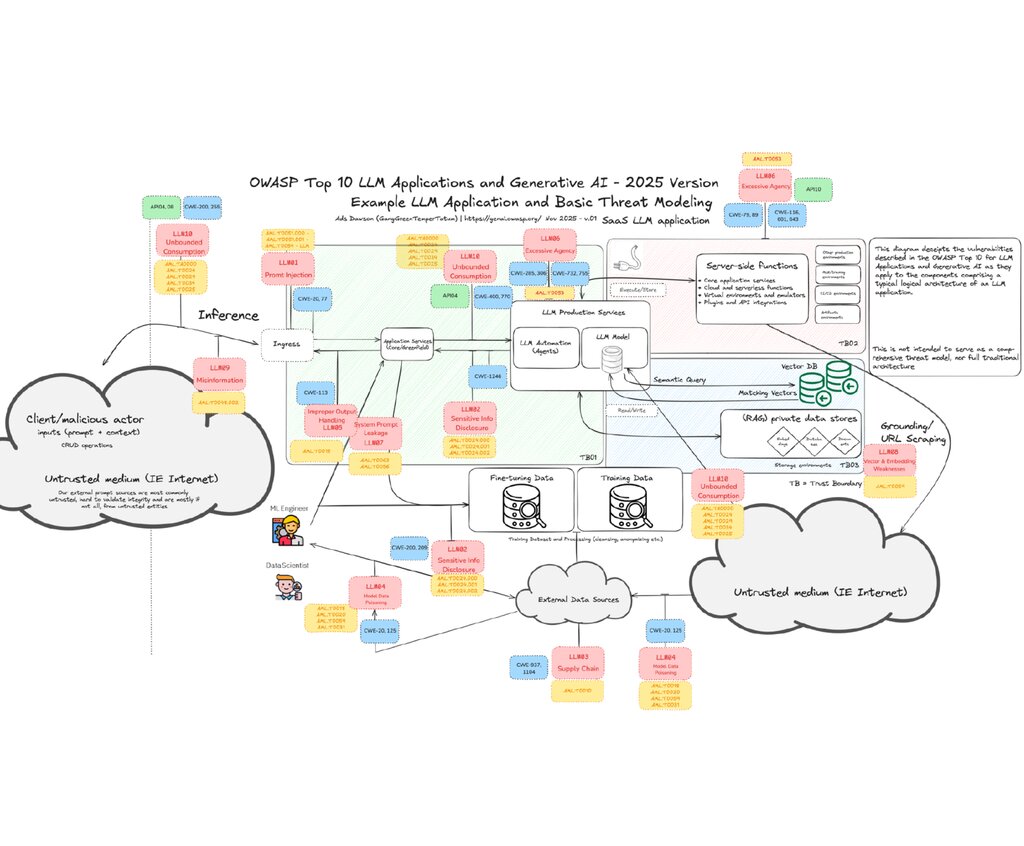
The OWASP Top 10 Risks for LLM Applications and Generative AI
LLM01:2025 Prompt Injection
A Prompt Injection Vulnerability occurs when user prompts alter the LLM’s behaviour or output in unintended ways. These inputs can affect the model even if they are imperceptible to humans; prompt injections do not need to be human-visible/readable, as long as the content is parsed by the model.
Prompt injection involves manipulating model responses through specific inputs to alter its behavior, which can include bypassing safety measures.
Example: A chatbot is tricked into exposing internal system data.
LLM02: 2025 Sensitive Information Disclosure
Large Language Models (LLMs), especially when embedded in applications, risk exposing sensitive data, proprietary algorithms, or confidential details through their output. This can result in unauthorized access to data, privacy violations, and intellectual property breaches.
Sensitive information can affect both the LLM and its application context. This includes personal identifiable information (PII), financial details, health records, confidential business data, security credentials, and legal documents. Proprietary models may also have unique training methods and source code considered sensitive, especially in closed or foundation models.
AI systems unintentionally leak: Customer data, Credentials or Proprietary business information
LLM03: 2025 Supply Chain Vulnerabilities
LLM supply chains are susceptible to various vulnerabilities that can compromise the integrity of training data, models, and deployment platforms. These risks can result in biased outputs, security breaches, or system failures. While traditional software vulnerabilities focus on issues like code flaws and dependencies, in ML the risks also extend to third-party pre-trained models and data. These external elements can be manipulated through tampering or poisoning attacks.
AI supply chain attacks are similar to traditional software supply chain attacks, but more opaque and harder to detect.
LLM04: Data and Model Poisoning
Data poisoning occurs when pre-training, fine-tuning, or embedding data is manipulated to introduce vulnerabilities, backdoors, or biases. This manipulation can compromise model security, performance, or ethical behaviour, leading to harmful outputs or impaired capabilities.
Common risks include degraded model performance, biased or toxic content, and exploitation of downstream systems.
Attackers inject malicious or biased data into training pipelines.
LLM05: 2025 Improper Output Handling
Improper Output Handling specifically refers to insufficient validation, sanitization, and handling of outputs generated by large language models before they are passed downstream to other components and systems. Since LLM-generated content can be controlled by prompt input, this behaviour is similar to providing users with indirect access to additional functionality.
LLM outputs are blindly trusted and executed.
Risk: SQL injection, XSS, privilege escalation and remote code execution on backend systems.
LLM06: 2025 Excessive Agency
Excessive Agency is the vulnerability that enables damaging actions to be performed in response to unexpected, ambiguous or manipulated outputs from an LLM, regardless of what is causing the LLM to malfunction. Common triggers include:
- hallucination/confabulation caused by poorly-engineered benign prompts, or just a poorly performing model;
- direct/indirect prompt injection from a malicious user, an earlier invocation of a malicious/compromised extension, or (in multi-agent/collaborative systems) a malicious/compromised peer agent.
AI systems are given too much autonomy.
LLM07: 2025 System Prompt Leakage
The system prompt leakage vulnerability in LLMs refers to the risk that the system prompts or instructions used to steer the behavior of the model can also contain sensitive information that was not intended to be discovered. System prompts are designed to guide the model’s output based on the application’s requirements, but may inadvertently contain secrets. When discovered, this information can be used to facilitate other attacks.
Hidden system instructions are exposed.
LLM08: 2025 Vector and Embedding Weaknesses
Vectors and embeddings pose significant security risks in systems that use Retrieval Augmented Generation (RAG) with Large Language Models (LLMs). Weaknesses in how vectors and embeddings are generated, stored, or retrieved can be exploited by malicious actions (intentional or unintentional) to inject harmful content, manipulate model outputs, or access sensitive information.
Risk: Unauthorized Access & Data Leakage, Cross-Context Information Leaks and Federation Knowledge Conflict, Behaviour Alteration, Poisoned knowledge bases
LLM09: 2025 Misinformation
Misinformation occurs when LLMs produce false or misleading information that appears credible. This vulnerability can lead to security breaches, reputational damage, and legal liability.
AI generates false but convincing outputs.
One of the major causes of misinformation is hallucination, when the LLM generates content that seems accurate but is fabricated. Hallucinations occur when LLMs fill gaps in their training data using statistical patterns, without truly understanding the content.
LLM10:2025 Unbounded Consumption
Unbounded Consumption refers to the process where a Large Language Model (LLM) generates outputs based on input queries or prompts. Inference is a critical function of LLMs, involving the application of learned patterns and knowledge to produce relevant responses or predictions.
Unbounded Consumption occurs when a Large Language Model (LLM) application allows users to conduct excessive and uncontrolled inferences, leading to risks such as denial of service (DoS), economic losses, model theft, and service degradation.
AI security is no longer about the model; it’s about the entire system around it. That includes:
- Identity (who can access AI)
- Data (what AI can see)
- Integrations (what AI can do)
- Governance (how AI is controlled)
The future of secure AI will be built on:
- Identity-first architecture
- Secure cloud foundations (AWS, Azure, and GCP)
- Continuous monitoring and governance
- AI-aware security frameworks
Secure Your AI Before It Becomes a Liability
If your organization is deploying AI tools without assessing the risks, you are operating with blind spots.
At Reputiva, we help organizations:
- Identify vulnerabilities in AI and cloud environments
- Secure Microsoft 365, Google Workspace, and multi-cloud platforms (AWS, Azure, and GCP)
- Implement Zero Trust principles for AI systems
- Prevent data leakage, prompt injection, and AI misuse


