Large Language Models (LLMs) are increasingly being integrated into business applications, customer service platforms, software development workflows, and enterprise automation systems. While organizations often focus on securing user inputs, many overlook an equally important security challenge: what happens after the AI generates a response?
According to the OWASP Top 10 for LLM Applications 2025, Improper Output Handling occurs when organizations fail to validate, sanitize, or securely process AI-generated outputs before passing them to downstream systems. In traditional application security, user input is considered untrusted. The same principle must now be applied to AI-generated content. An LLM can be influenced by prompts, external content, or indirect prompt-injection attacks, potentially rendering its output dangerous if executed automatically.
What is Improper Output Handling?
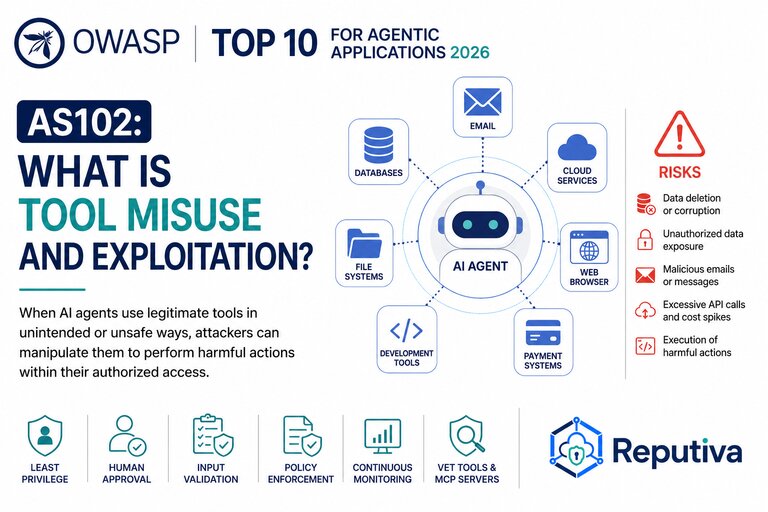
Improper Output Handling refers to insufficient validation, sanitization, and handling of the outputs generated by large language models before they are passed downstream to other components and systems. Successful exploitation of an Improper Output Handling vulnerability can result in XSS and CSRF in web browsers as well as SSRF, privilege escalation, or remote code execution on backend systems.
Improper Output Handling vs Overreliance
Improper Output Handling deals with LLM-generated outputs before they are passed downstream, whereas Overreliance focuses on the accuracy and appropriateness of LLM outputs.
Common Examples of Improper Output Handling Vulnerability
- LLM output is entered directly into a system shell or similar function such as exec or eval, resulting in remote code execution.
- JavaScript or Markdown is generated by the LLM and returned to a user. The code is then interpreted by the browser, resulting in XSS.
- LLM-generated SQL queries are executed without proper parameterization, leading to SQL injection.
- LLM output is used to construct file paths without proper sanitization, potentially resulting in path traversal vulnerabilities.
- LLM-generated content is used in email templates without proper escaping, which can lead to phishing attacks.
Prevention and Mitigation Strategies
- Treat the model as any other user, adopting a zero-trust approach, and apply proper input validation on responses coming from the model to backend functions.
- Follow the OWASP ASVS (Application Security Verification Standard) guidelines to ensure effective input validation and sanitization.
- Encode model output back to users to mitigate undesired code execution by JavaScript or Markdown. OWASP ASVS provides detailed guidance on output encoding.
- Implement context-aware output encoding based on where the LLM output will be used (e.g., HTML encoding for web content, SQL escaping for database queries).
- Use parameterized queries or prepared statements for all database operations involving LLM output.
- Employ strict Content Security Policies (CSP) to mitigate the risk of XSS attacks from LLM-generated content.
- Implement robust logging and monitoring systems to detect unusual patterns in LLM outputs that might indicate exploitation attempts.
Attack Scenarios and Real-World Examples – Improper Output Handling
Scenario #1: AI-Generated Code Leads to Remote Code Execution
An application utilizes an LLM extension to generate responses for a chatbot feature. The extension also offers a number of administrative functions accessible to another privileged LLM. The general-purpose LLM directly passes its response, without proper output validation, to the extension, which then shuts down for maintenance.
Real-World Example: ChatGPT Plugin Exploitation Research
Security researcher Johann Rehberger demonstrated how prompt injection attacks against AI plugins could manipulate connected applications into performing unintended actions, accessing sensitive data, and executing privileged operations.
Scenario 2: Cross-Site Scripting (XSS) Through AI-Generated Content
A web app uses an LLM to generate content from user text prompts without output sanitization. An attacker could submit a crafted prompt, causing the LLM to return an unsanitized JavaScript payload that could lead to XSS when rendered in a victim’s browser. Insufficient validation of prompts enabled this attack.
Real-World Example: Prompt Injection via Markdown Images
Security Researchers demonstrated how malicious Markdown generated by ChatGPT could exfiltrate chat data through embedded image URLs and tracking mechanisms.
Scenario #3: AI-Generated SQL Queries Destroy Data
An LLM allows users to craft SQL queries for a backend database through a chat-like feature. A user requests a query to delete all database tables. If the LLM-crafted query is not scrutinized, all database tables will be deleted.
Real-World Example: Amazon Q Vulnerability
Security Researchers discovered vulnerabilities in Amazon Q, where prompt manipulation could cause unintended behaviour and potentially influence generated code recommendations.
Scenario #4: Prompt Injection + Data Exfiltration
A user utilizes a website summarizer tool powered by an LLM to generate a concise summary of an article. The website includes a prompt injection that instructs the LLM to capture sensitive content from either the website or the user’s conversation. From there, the LLM can encode the sensitive data and send it to an attacker-controlled server without any output validation or filtering.
Real-World Example: Indirect Prompt Injection Research
Kai Greshake and other researchers demonstrated how hidden instructions embedded in webpages could manipulate AI systems to leak conversation data and perform unintended actions.
Scenario 5: AI Hallucinates Software Packages
An LLM is used in a software company to generate code from natural language inputs, aiming to streamline development tasks. While efficient, this approach risks exposing sensitive information, creating insecure data-handling practices, or introducing vulnerabilities such as SQL injection. The AI may also hallucinate non-existent software packages, potentially leading developers to download malware-infected resources. Thorough code review and verification of suggested packages are crucial to prevent security breaches, unauthorized access, and system compromises.
Real-World Example: Package Hallucination Research
Researchers from Lasso Security found that coding assistants frequently hallucinate package names. Attackers can register these fake packages and distribute malware through trusted repositories.
Scenario 6: AI-Generated Email Content Enables Phishing
An LLM is used to generate dynamic email templates for a marketing campaign. An attacker manipulates the LLM to include malicious JavaScript within the email content. If the application doesn’t properly sanitize the LLM output, this could lead to XSS attacks on recipients who view the email in vulnerable email clients.
Real-World Example: Business Email Compromise Enhanced by AI
Multiple security vendors, including Microsoft Security and Google Cloud Security, have documented how generative AI is being used to create highly convincing phishing emails that improve attacker success rates.
AI Output Is the New User Input
As organizations adopt AI copilots, frontier models, agents, and automation platforms, security teams must rethink traditional trust boundaries. At Reputiva, we believe organizations should adopt a Zero Trust approach to AI outputs:
- Treat every AI response as untrusted until verified.
- Implement validation and sanitization controls before outputs reach downstream systems.
- Apply least-privilege access to AI-integrated applications.
- Establish human approval workflows for high-risk actions.
- Continuously monitor AI-driven workflows for anomalous behaviour.
The next generation of cyberattacks will not always target infrastructure directly; they will target the AI systems that organizations increasingly trust to make decisions and take actions on their behalf.
Organizations that secure AI outputs today will be better positioned to safely scale AI adoption tomorrow.
Secure Your AI workflows before Attackers Do
AI can accelerate productivity, automate workflows, and improve customer experiences, but only when deployed securely. Reputiva helps organizations assess and secure AI-enabled environments through:
- AI Security Assessments
- Secure AI Architecture Reviews
- Cloud Security Assessments (AWS, Azure, and GCP)
- Identity and Access Management Reviews
- AI Governance and Risk Management Programs
Planning to deploy AI agents, copilots, or LLM-powered applications? Start with a security assessment to ensure AI outputs don’t become your next attack vector.
Reputiva
Reputiva is a cloud, cybersecurity, and FinOps advisory firm helping SMEs reduce cyber risk, strengthen cloud environments, and manage technology costs with confidence. We publish practical insights on cloud security, identity, AI risk, compliance, and digital transformation.