AI agents are moving beyond simple chatbot interactions. Unlike traditional Large Language Models that mainly generate content, AI agents can perceive context, make decisions, interact with tools, and take actions on behalf of users or organizations. That shift creates enormous productivity potential, but it also introduces a new security reality: when AI systems can act, mistakes and attacks can have real-world consequences.
Google’s paper, Google’s Approach for Secure AI Agents: An Introduction, highlights two major risks organizations must pay close attention to: rogue actions and sensitive data disclosure. Rogue actions occur when an agent takes harmful, unintended, or policy-violating actions. Sensitive data disclosure occurs when an agent improperly exposes confidential or private information. These risks can be triggered by prompt injection, poor permission design, weak oversight, insecure memory, or unsafe tool access.
The promise and risks of AI agents
AI Agents
AI systems are designed to perceive their environment, make decisions, and take autonomous actions to achieve user-defined goals. Unlike standard Large Language Models (LLMs) that primarily generate content, agents act. They leverage AI reasoning to interact with other systems and execute tasks, ranging from simple automation like categorizing incoming service requests to complex, multi-step planning such as researching a topic across multiple sources, summarizing the findings, and drafting an email to a team.
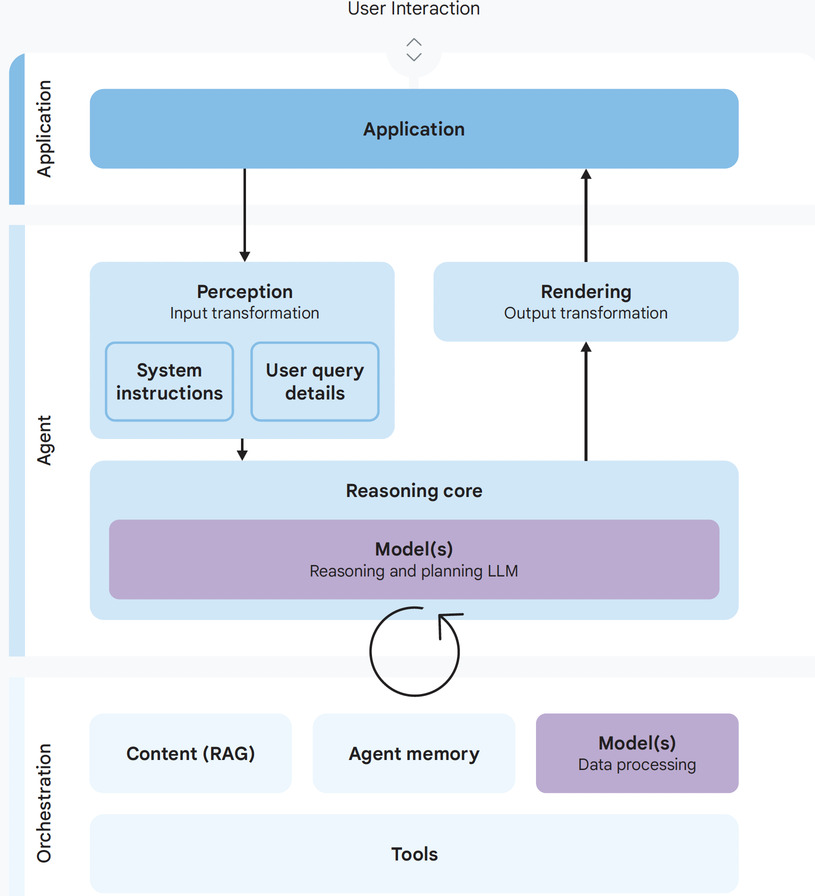
Key risks: Rogue actions and sensitive data disclosure
The very nature of AI agents introduces new risks stemming from several inherent characteristics. The underlying AI models can be unpredictable, as their non-deterministic nature means their behaviour isn’t always repeatable even with the same input. Complex, emergent behaviours can arise that weren’t explicitly programmed. Higher levels of autonomy in decision-making increase the scope and impact of errors, as well as the potential for vulnerabilities to malicious actors.
- Rogue actions (unintended, harmful, or policy-violating actions)
- Sensitive data disclosure (unauthorized revelation of private information).
Risk 1: Rogue actions
Rogue actions—unintended, harmful, or policy-violating agent behaviours— represent a primary security risk for AI agents.
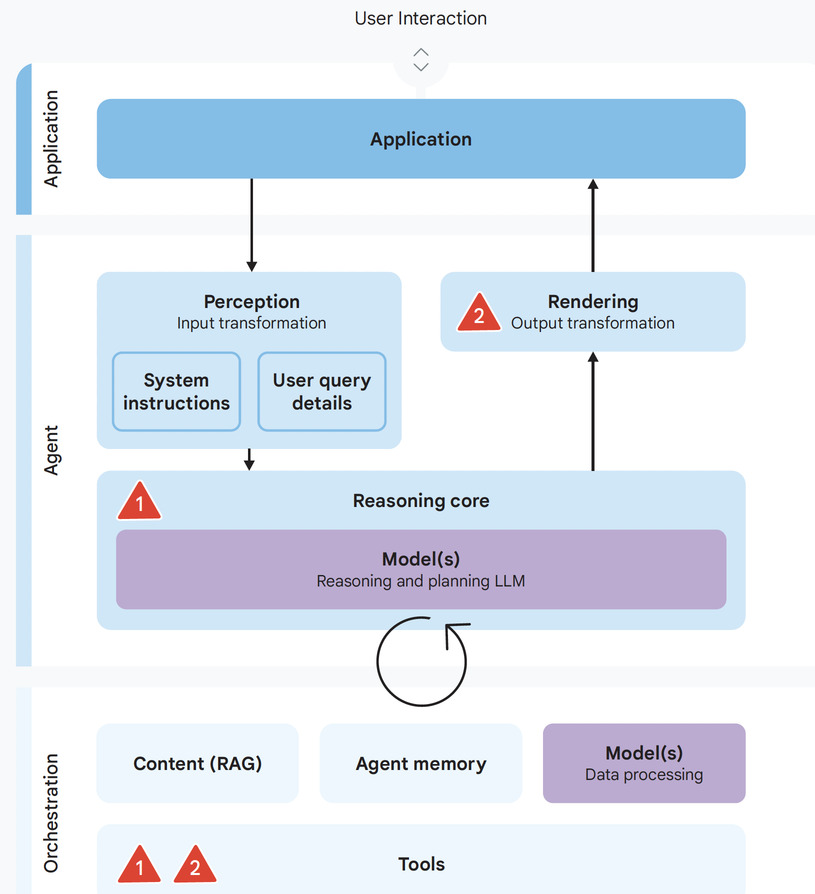
A key cause is prompt injection: malicious instructions hidden within processed data (like files, emails, or websites) can trick the agent’s core AI model, hijacking its planning or reasoning phases. The model misinterprets embedded data as instructions, executing attacker commands with the user’s authority. For example, an agent processing a malicious email might be coerced into leaking user data rather than performing the requested task.
Risk 2: Sensitive data disclosure
This critical risk involves an agent improperly revealing private or confidential information. A primary method for achieving sensitive data disclosure is data exfiltration. This involves tricking the agent into making sensitive information visible to an attacker. Attackers often achieve this by exploiting agent actions and their side effects, often through prompt injection.
Attackers can methodically guide an agent through a sequence of actions. They might trick the agent into retrieving sensitive data and then leaking it through actions, such as embedding data in a URL the agent is prompted to visit, or hiding secrets in code commit messages.
Google’s Secure AI Framework (SAIF)
Secure AI Framework (SAIF), a conceptual framework for secure AI systems.
Core principles for agent security
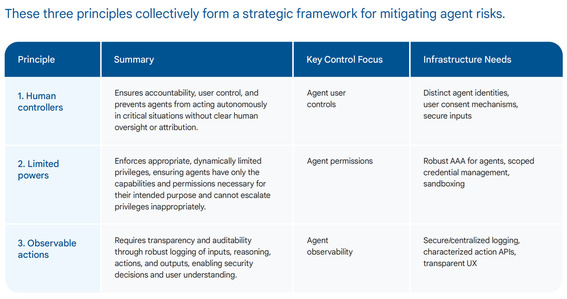
Principle 1: Agents must have well-defined human controllers
Agents typically act as proxies or assistants for humans, inheriting privileges to access resources and perform actions. Therefore, it is essential for security and accountability that agents operate under clear human oversight.
This principle mandates that systems must be able to reliably distinguish instructions originating from an authorized controlling user versus any other input, especially potentially untrusted data processed by the agent.
Controls: This principle relies on effective Agent User Controls, supported by infrastructure that provides distinct agent identities and secure input channels to differentiate user commands.
Principle 2: Agent powers must have limitations
An agent’s powers—the actions it can take and the resources it can access—must be carefully limited in alignment with its intended purpose and its controlling user’s risk tolerance.
This principle extends traditional least privilege by requiring an agent’s permissions to be dynamically aligned with its specific purpose and current user intent, rather than just being statically minimized. This distinction is crucial because model-based agents operate in potentially unbounded ecosystems and are susceptible to reasoning errors, necessitating context-aware limitations that go beyond the typical scope considered for human users or traditional software.
Controls: Implementing this principle requires defined Agent Permissions controls, enforced by robust Authentication, Authorization, and Auditing (AAA) infrastructure tailored for agents, and the use of scoped credentials, such as OAuth tokens, to manage access securely.
Principle 3: Agent actions and planning must be observable
Trust, effective debugging, security auditing, incident response, and user understanding all hinge on transparency into the agent’s activities. Effective observability also means that the properties of the actions an agent can take—such as whether an action is read-only versus state-changing, or if it handles sensitive data—must be clearly characterized. This metadata is crucial for automated security mechanisms and human reviewers.
Controls: Effective Agent Observability controls are crucial, necessitating infrastructure investments in secure, centralized logging systems and standardized APIs that clearly characterize action properties and potential side effects.
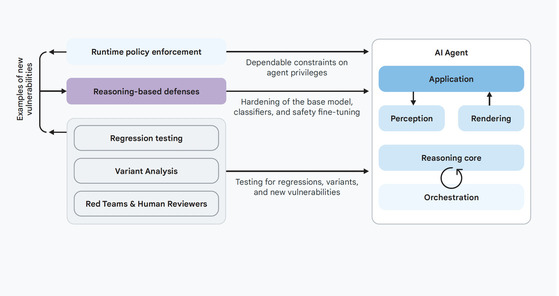
Google’s approach: A hybrid defence-in-depth
Google recommends a hybrid defence-in-depth approach for securing AI agents. This approach combines traditional deterministic controls with reasoning-based defences. The goal is to create multiple layers of protection around the agent so that, even if one layer fails, another can mitigate the risk of harmful outcomes.
This is a practical and important message for organizations: do not assume that one control will be enough.
A secure AI agent environment should include technical controls, identity controls, permission boundaries, human approval workflows, logging, testing, red teaming, and continuous monitoring.
AI Agent Security is really Identity, Permission, and Oversight Security
From Reputiva’s perspective, the most important insight from Google’s approach is that AI agent security is not only an AI problem. It is also an identity and access management problem, a cloud security problem, a data governance problem, and an operational risk problem.
Google’s recommended approach is based on a hybrid defence-in-depth model that combines deterministic controls, such as runtime policy enforcement, with reasoning-based defences, such as model-based risk detection, adversarial testing, and guard models. This matters because organizations cannot rely only on the AI model to “behave safely.” At the same time, traditional security controls alone may not have enough context to effectively manage every agent decision.
For organizations adopting AI agents, Reputiva sees three practical priorities:
First, every AI agent should have a clearly defined human controller. The organization must know who the agent is acting for, what authority it has, and when human approval is required.
Second, agent powers must be limited. An AI agent should not automatically inherit broad user permissions. It should operate with scoped access, task-specific privileges, and clear limits on high-risk actions.
Third, agent activity must be observable. Organizations need logs showing what the agent saw, which tools it used, which actions it attempted, which data it accessed, and when human approval was requested.
The future of AI adoption will not be determined only by who deploys the most advanced models. It will be shaped by who can deploy AI agents safely, with the right permissions, monitoring, and governance from day one.
Planning to deploy AI Agents? Start with a security readiness review
AI agents can improve productivity, automate workflows, and support better decision-making, but they must be deployed with strong controls around identity, permissions, data access, logging, and human oversight.
Reputiva helps organizations assess their AI, cloud, and cybersecurity readiness before new tools create avoidable risk.
Book a consultation with Reputiva to review your AI agent security posture, cloud environment, identity controls, and data protection risks before deploying agentic AI at scale.


